


Getting Started¶
Making an environment¶
Here is a quick example of how to create an environment:
import gymnasium
import highway_env
from matplotlib import pyplot as plt
%matplotlib inline
env = gymnasium.make('highway-v0', render_mode='rgb_array')
env.reset()
for _ in range(3):
action = env.unwrapped.action_type.actions_indexes["IDLE"]
obs, reward, done, truncated, info = env.step(action)
env.render()
plt.imshow(env.render())
plt.show()
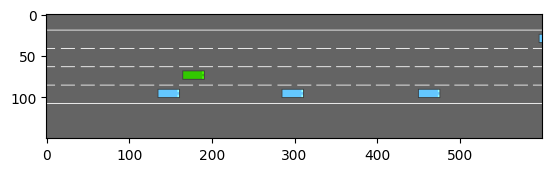
All the environments¶
Here is the list of all the environments available and their descriptions:
Configuring an environment¶
The observations, actions, dynamics and rewards
of an environment are parametrized by a configuration, defined as a
config dictionary.
For example, the number of lanes can be changed with:
env = gymnasium.make(
"highway-v0",
config={"lanes_count": 2},
render_mode='rgb_array',
)
env.reset()
plt.imshow(env.render())
plt.show()

After environment creation, the configuration can be accessed using the
config attribute.
import pprint
pprint.pprint(env.unwrapped.config)
{'action': {'type': 'DiscreteMetaAction'},
'centering_position': [0.3, 0.5],
'collision_reward': -1,
'controlled_vehicles': 1,
'duration': 40,
'ego_spacing': 2,
'high_speed_reward': 0.4,
'initial_lane_id': None,
'lane_change_reward': 0,
'lanes_count': 2,
'manual_control': False,
'neighbour_vehicles_connected_lanes': False,
'normalize_reward': True,
'observation': {'type': 'Kinematics'},
'offroad_terminal': False,
'offscreen_rendering': True,
'other_vehicles_type': 'highway_env.vehicle.behavior.IDMVehicle',
'policy_frequency': 1,
'real_time_rendering': False,
'render_agent': True,
'reward_speed_range': [20, 30],
'right_lane_reward': 0.1,
'scaling': 5.5,
'screen_height': 150,
'screen_width': 600,
'show_trajectories': False,
'simulation_frequency': 15,
'vehicles_count': 50,
'vehicles_density': 1}
Training an agent¶
Reinforcement Learning agents can be trained using libraries such as eleurent/rl-agents, openai/baselines or Stable Baselines3.
Here is an example of SB3’s DQN implementation trained on highway-fast-v0 with its default kinematics observation and an MLP model.
![]()
import gymnasium
import highway_env
from stable_baselines3 import DQN
env = gymnasium.make("highway-fast-v0")
model = DQN('MlpPolicy', env,
policy_kwargs=dict(net_arch=[256, 256]),
learning_rate=5e-4,
buffer_size=15000,
learning_starts=200,
batch_size=32,
gamma=0.8,
train_freq=1,
gradient_steps=1,
target_update_interval=50,
verbose=1,
tensorboard_log="highway_dqn/")
model.learn(int(2e4))
model.save("highway_dqn/model")
# Load and test saved model
model = DQN.load("highway_dqn/model")
while True:
done = truncated = False
obs, info = env.reset()
while not (done or truncated):
action, _states = model.predict(obs, deterministic=True)
obs, reward, done, truncated, info = env.step(action)
env.render()
A full run takes about 25mn on my laptop (fps=14). The following results are obtained:
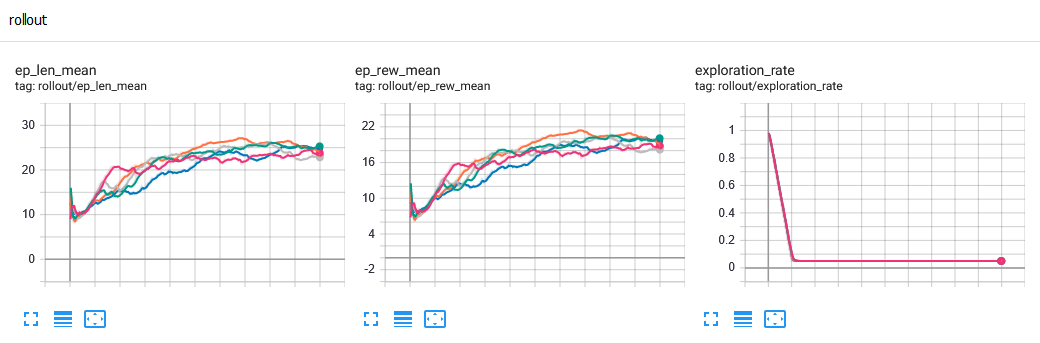
Training curves, for 5 random seeds.¶
Video of an episode run with the trained policy.¶
Note
There are several ways to get better performances. For instance, SB3 provides only vanilla Deep Q-Learning and has no extensions such as Double-DQN, Dueling-DQN and Prioritized Experience Replay. However, eleurent/rl-agents’s implementation of DQN does provide those extensions, which yields better results. Improvements can also be obtained by changing the observation type or the model, see the FAQ.
Examples on Google Colab¶
Several scripts and notebooks to train driving policies on HighwayEnv are available on this page.
Here are a few of them:
Highway with image observations and a CNN model ![]() Train SB3’s DQN on
Train SB3’s DQN on highway-fast-v0 , but using image observations and a CNN model for the value function.
Trajectory Planning on Highway ![]() Plan a trajectory on
Plan a trajectory on highway-v0 using the OPD [HM08] implementation from eleurent/rl-agents.
A Model-based Reinforcement Learning tutorial on Parking ![]() A tutorial written for RLSS 2019 and demonstrating the principle of model-based reinforcement learning on the
A tutorial written for RLSS 2019 and demonstrating the principle of model-based reinforcement learning on the parking-v0 task.
Parking with Hindsight Experience Replay ![]() Train a goal-conditioned
Train a goal-conditioned parking-v0 policy using the HER [AWR+17] implementation from stable-baselines.
Intersection with DQN and social attention ![]() Train an
Train an intersection-v0 crossing policy using the social attention architecture [LM19] and the DQN implementation from eleurent/rl-agents.