


The Multi-Agent setting¶
Most environments can be configured to a multi-agent version. Here is how:
Increase the number of controlled vehicles¶
To that end, update the environment configuration to increase controlled_vehicles
import gymnasium
import highway_env
env = gymnasium.make(
"highway-v0",
render_mode="rgb_array",
config={
"controlled_vehicles": 2, # Two controlled vehicles
"vehicles_count": 1, # A single other vehicle, for the sake of visualisation
}
)
env.reset(seed=0)
from matplotlib import pyplot as plt
%matplotlib inline
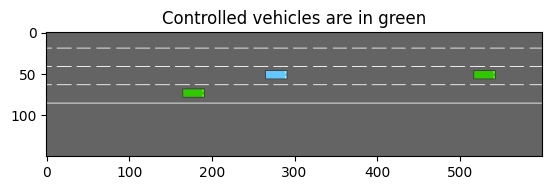
plt.imshow(env.render())
plt.title("Controlled vehicles are in green")
plt.show()
Change the action space¶
Right now, since the action space has not been changed, only the first vehicle is controlled by env.step(action).
In order for the environment to accept a tuple of actions, its action type must be set to MultiAgentAction
The type of actions contained in the tuple must be described by a standard action configuration in the action_config field.
env.unwrapped.config.update({
"action": {
"type": "MultiAgentAction",
"action_config": {
"type": "DiscreteMetaAction",
}
}
})
env.reset()
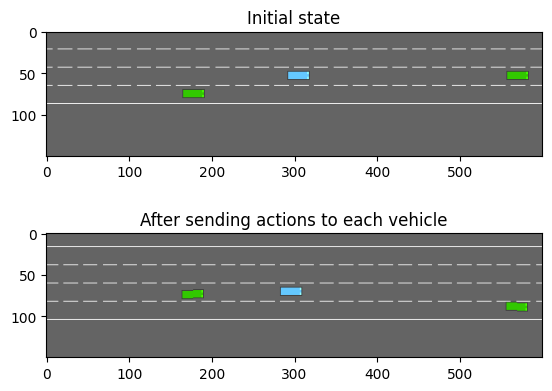
_, (ax1, ax2) = plt.subplots(nrows=2)
ax1.imshow(env.render())
ax1.set_title("Initial state")
# Make the first vehicle change to the left lane, and the second one to the right
action_1, action_2 = 0, 2 # See highway_env.envs.common.action.DiscreteMetaAction.ACTIONS_ALL
env.step((action_1, action_2))
ax2.imshow(env.render())
ax2.set_title("After sending actions to each vehicle")
plt.show()
Change the observation space¶
In order to actually decide what action_1 and action_2 should be, both vehicles must generate their own observations.
As before, since the observation space has not been changed no far, the observation only includes that of the first vehicle.
In order for the environment to return a tuple of observations – one for each agent –, its observation type must be set to MultiAgentObservation
The type of observations contained in the tuple must be described by a standard observation configuration in the observation_config field.
env = gymnasium.make(
"highway-v0",
render_mode="rgb_array",
config={
"observation": {
"type": "MultiAgentObservation",
"observation_config": {
"type": "Kinematics",
}
}
}
)
obs, info = env.reset()
import pprint
pprint.pprint(obs)
(array([[ 1. , 0.89330107, 0.5 , 0.3125 , 0. ],
[ 1. , 0.11133764, 0.25 , -0.03969451, 0. ],
[ 1. , 0.22504443, -0.25 , -0.0230743 , 0. ],
[ 1. , 0.3230369 , 0. , -0.02129776, 0. ],
[ 1. , 0.42214277, -0.25 , -0.0349044 , 0. ]],
dtype=float32),)
Wrapping it up¶
Here is a pseudo-code example of how a centralized multi-agent policy could be trained:
# Multi-agent environment configuration
env.unwrapped.config.update({
"controlled_vehicles": 2,
"observation": {
"type": "MultiAgentObservation",
"observation_config": {
"type": "Kinematics",
}
},
"action": {
"type": "MultiAgentAction",
"action_config": {
"type": "DiscreteMetaAction",
}
}
})
# Dummy RL algorithm
class Model:
""" Dummy code for an RL algorithm, which predicts an action from an observation,
and update its model from observed transitions."""
def predict(self, obs):
return 0
def update(self, obs, action, next_obs, reward, info, done, truncated):
pass
model = Model()
# A training episode
obs, info = env.reset()
done = truncated = False
while not (done or truncated):
# Dispatch the observations to the model to get the tuple of actions
action = tuple(model.predict(obs_i) for obs_i in obs)
# Execute the actions
next_obs, reward, done, truncated, info = env.step(action)
# Update the model with the transitions observed by each agent
for obs_i, action_i, next_obs_i in zip(obs, action, next_obs):
model.update(obs_i, action_i, next_obs_i, reward, info, done, truncated)
obs = next_obs
For example, this is supported by eleurent/rl-agents’s DQN implementation, and can be run with
cd <path/to/rl-agents/scripts>
python experiments.py evaluate configs/IntersectionEnv/env_multi_agent.json \
configs/IntersectionEnv/agents/DQNAgent/ego_attention_2h.json \
--train --episodes=3000
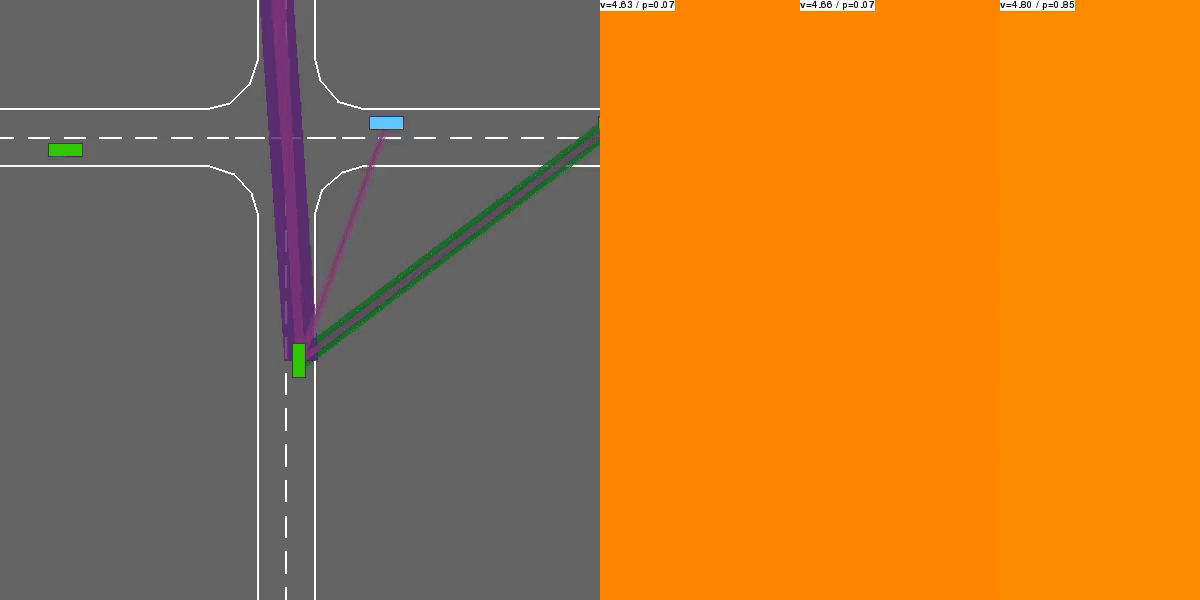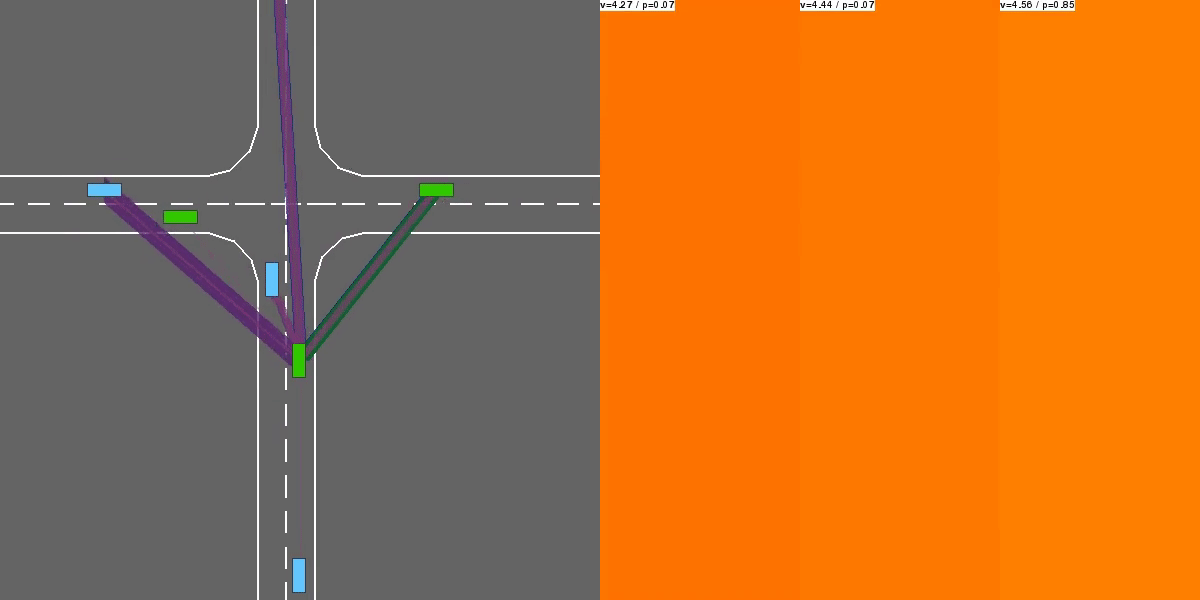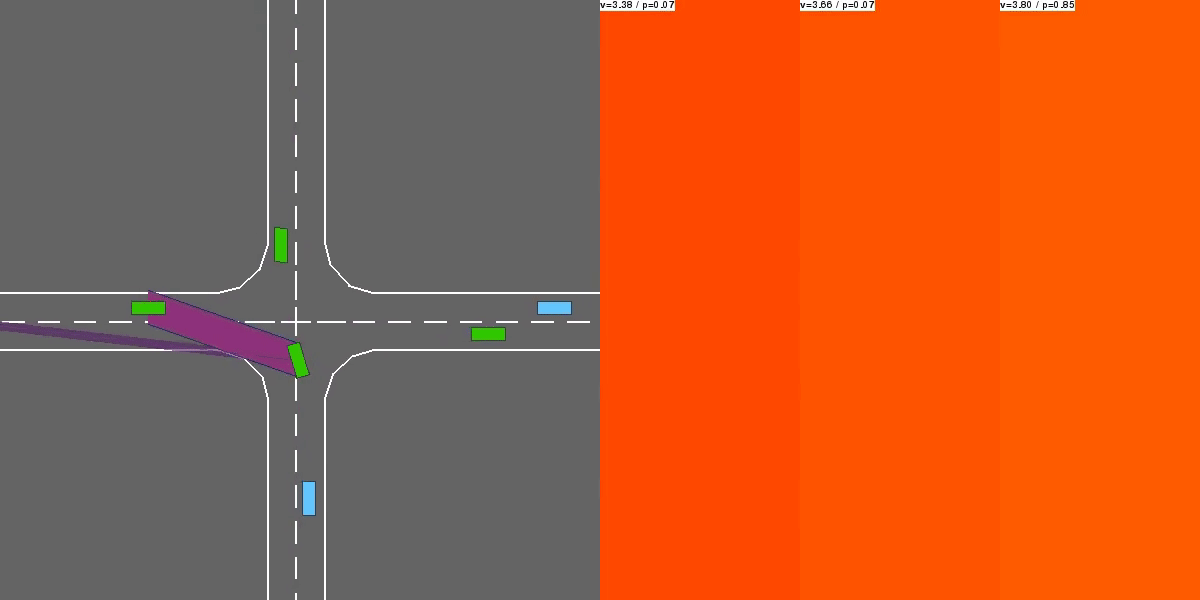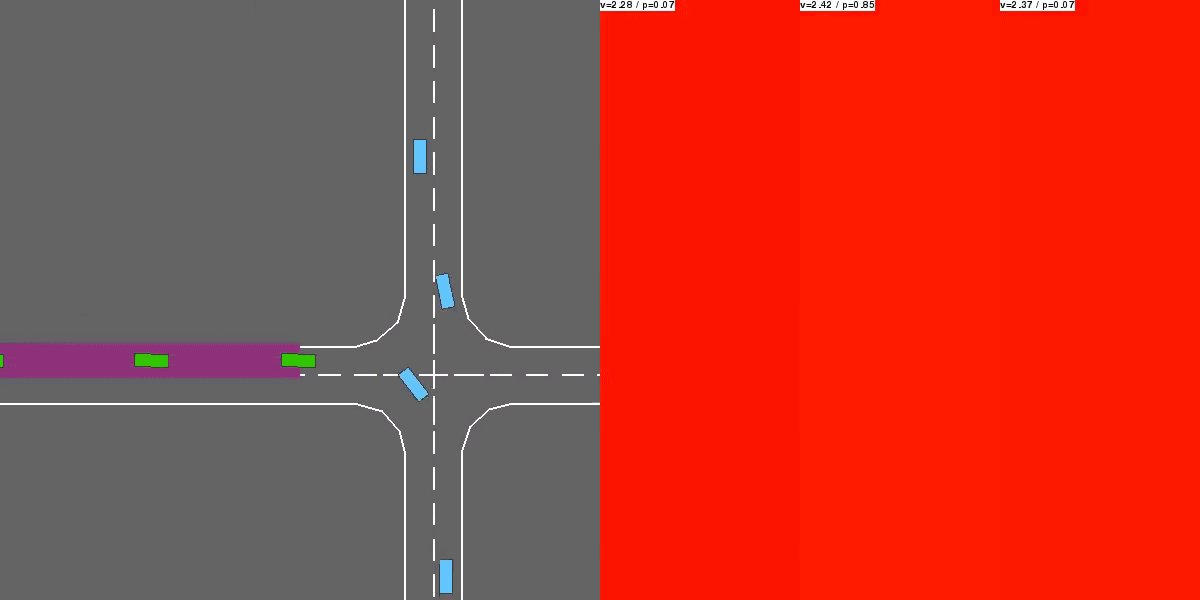
Video of a multi-agent episode with the trained policy.¶